
Data preparation remains the most critical—and often most overlooked—phase of any successful machine learning project. As we enter 2025, studies show that data scientists still spend 45-60% of their time on data preparation tasks, with advanced organizations reporting that proper data preprocessing can improve model accuracy by up to 70%.
This definitive 2025 guide will walk you through the exact, battle-tested framework that top AI teams use to transform raw, messy data into a clean, machine-ready dataset. Whether you’re a beginner working on your first Kaggle competition or a seasoned professional building enterprise AI systems, this step-by-step tutorial will give you the complete data preparation toolkit for 2025.
Why Data Preparation Matters More Than Ever in 2025

The machine learning landscape has evolved dramatically, but one principle remains unchanged: garbage in, garbage out. Proper data preparation in 2025 is crucial because:
- Foundation Models & LLMs still require clean, structured data for fine-tuning
- AI Regulations (EU AI Act, US Executive Orders) mandate data quality and fairness
- Edge AI Deployment demands optimized, efficient data pipelines
- Multi-Modal Learning requires sophisticated data integration techniques
- AutoML Systems perform better with well-prepared input data
Think of data preparation as the difference between building on solid ground versus quicksand—your model’s entire success depends on this foundation.
The 8-Step Data Preparation Framework for 2025
Here’s the complete, updated framework that incorporates the latest 2025 best practices:
Step 1: Data Collection & Modern Data Stack Integration
2025 Update: Data sources have multiplied, requiring sophisticated integration strategies.
Key Activities:
- Multi-source aggregation (APIs, cloud storage, data lakes, real-time streams)
- Data lineage tracking for compliance and reproducibility
- Initial data profiling to understand volume, variety, and velocity
- Privacy-preserving collection following GDPR/CCPA guidelines
2025 Tools & Techniques:
python
# Modern data collection with Python
import pandas as pd
import pyarrow.parquet as pq
from sklearn.datasets import fetch_openml
import great_expectations as ge
# Collect from multiple sources
df_api = pd.read_json('https://api.yourdata.com/v2/records')
df_cloud = pd.read_parquet('s3://your-bucket/data-2025.parquet')
df_local = pd.read_csv('local_dataset.csv')
# Data quality assessment
df_ge = ge.from_pandas(df_api)
results = df_ge.validate()
Step 2: Comprehensive Data Understanding & Profiling
2025 Update: Automated EDA tools have become standard, with AI-assisted insights.
Key Activities:
- Automated data profiling with AI-powered tools
- Data quality assessment scoring
- Domain context integration with business experts
- Bias and fairness detection in initial datasets
Modern EDA Approach:
python
# 2025 Automated EDA
from ydata_profiling import ProfileReport
import sweetviz as sv
import dataprep
# Generate comprehensive profile
profile = ProfileReport(df, title="Data Profile 2025")
profile.to_file("data_profile.html")
# Automated bias detection
from aif360.datasets import BinaryLabelDataset
from aif360.metrics import DatasetMetric
# Check for protected attribute bias
protected_dataset = BinaryLabelDataset(...)
metric = DatasetMetric(protected_dataset, ...)
print(f"Disparate impact: {metric.disparate_impact()}")
Step 3: Advanced Data Cleaning & Quality Enhancement

2025 Update: ML-powered cleaning tools and synthetic data generation for missing values.
Key Activities:
- AI-powered imputation using neural networks and generative methods
- Automated outlier detection with ensemble methods
- Cross-validation aware cleaning to prevent data leakage
- Data augmentation for small datasets
Modern Cleaning Techniques:
python
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer
from sklearn.ensemble import RandomForestRegressor
from fancyimpute import KNN, NuclearNormMinimization
# Advanced imputation strategies
imputer = IterativeImputer(estimator=RandomForestRegressor(),
max_iter=10, random_state=42)
df_imputed = imputer.fit_transform(df)
# Automated outlier detection with multiple methods
from pyod.models.ecod import ECOD
from pyod.models.knn import KNN
detector = ECOD()
outlier_labels = detector.fit_predict(df)
df_clean = df[outlier_labels == 0]
Step 4: Smart Feature Engineering & Creation
2025 Update: Automated feature engineering with deep learning and domain adaptation.
Key Activities:
- Automated feature generation using featuretools
- Deep feature synthesis with neural networks
- Domain-specific feature engineering (time series, NLP, vision)
- Feature stores for reusability and consistency
Advanced Feature Engineering:
python
import featuretools as ft
import tsfresh
from feature_engine.creation import MathematicalCombination
# Automated deep feature synthesis
es = ft.EntitySet()
es = es.entity_from_dataframe(entity_id='data', dataframe=df, index='id')
features, feature_defs = ft.dfs(entityset=es, target_entity='data',
max_depth=2, verbose=True)
# Time-series specific features
from tsfresh import extract_features
ts_features = extract_features(df, column_id='id', column_sort='timestamp')
# Automated feature stores
from feast import FeatureStore
store = FeatureStore(repo_path=".")
feature_vector = store.get_online_features(...)
Step 5: Advanced Feature Selection & Dimensionality Reduction

2025 Update: Model-agnostic feature importance and causal feature selection.
Key Activities:
- Model-agnostic feature importance with SHAP and LIME
- Causal inference for feature selection
- Automated feature selection with meta-learning
- Multi-collinearity detection with advanced metrics
Modern Feature Selection:
python
import shap from sklearn.inspection import permutation_importance from causalml.feature_selection import FeatureSelection # SHAP-based feature importance explainer = shap.TreeExplainer(model) shap_values = explainer.shap_values(X) shap.summary_plot(shap_values, X) # Causal feature selection fs = FeatureSelection() selected_features = fs.get_features(X, y, method='lasso') # Permutation importance result = permutation_importance(model, X_test, y_test, n_repeats=10)
Step 6: Data Transformation & Modern Encoding
2025 Update: Target encoding revival, transformer-based encodings, and adaptive scaling.
Key Activities:
- Advanced encoding strategies (target encoding, leave-one-out)
- Transformer-based embeddings for high-cardinality features
- Adaptive scaling that learns from data distributions
- Multi-modal data integration techniques
2025 Transformation Methods:
python
from sklearn.preprocessing import RobustScaler, QuantileTransformer
from category_encoders import TargetEncoder, LeaveOneOutEncoder
from sklearn.compose import ColumnTransformer
# Modern encoding pipeline
preprocessor = ColumnTransformer(
transformers=[
('num', RobustScaler(), numerical_features),
('cat_target', TargetEncoder(), high_cardinality_features),
('cat_ohe', OneHotEncoder(drop='first'), low_cardinality_features)
],
remainder='drop'
)
# Advanced scaling for non-normal distributions
quantile_transformer = QuantileTransformer(
output_distribution='normal', random_state=42
)
Step 7: Strategic Data Splitting & Validation
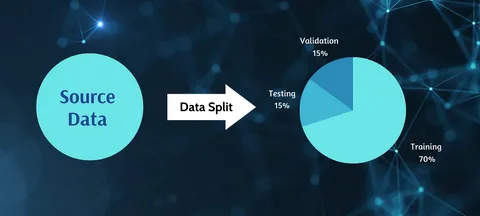
2025 Update: Temporal validation, group-aware splitting, and fairness-aware partitioning.
Key Activities:
- Time-aware splitting for temporal data
- Group-wise splitting to prevent data leakage
- Fairness-aware splitting to ensure representation
- Cross-validation strategies for specific data types
Modern Splitting Approaches:
python
from sklearn.model_selection import TimeSeriesSplit, GroupKFold
from sklearn.model_selection import StratifiedShuffleSplit
# Time series splitting
tscv = TimeSeriesSplit(n_splits=5)
for train_idx, test_idx in tscv.split(X):
X_train, X_test = X.iloc[train_idx], X.iloc[test_idx]
# Group-wise splitting (prevent data leakage)
group_kfold = GroupKFold(n_splits=5)
for train_idx, test_idx in group_kfold.split(X, y, groups):
X_train, X_test = X.iloc[train_idx], X.iloc[test_idx]
# Fairness-aware splitting
from aif360.sklearn.split import FairStratifiedShuffleSplit
fsss = FairStratifiedShuffleSplit(...)
Step 8: Production Data Validation & Monitoring
2025 Update: Continuous data validation and drift detection in production.
Key Activities:
- Data schema validation with Great Expectations
- Data drift detection with Evidently AI
- Quality monitoring in production pipelines
- Automated retraining triggers based on data changes
Production Validation:
python
import great_expectations as ge
from evidently.report import Report
from evidently.metric_preset import DataDriftPreset
# Data validation suite
suite = ge.dataset.PandasDataset(df)
suite.expect_column_to_exist("customer_id")
suite.expect_column_values_to_be_between("age", 18, 100)
# Data drift monitoring
data_drift_report = Report(metrics=[DataDriftPreset()])
data_drift_report.run(reference_data=df_train, current_data=df_current)
data_drift_report.show()
2025 Data Preparation Automation Tools
Emerging Solutions:
- AutoML Platforms: DataRobot, H2O.ai, Azure Automated ML
- Feature Stores: Feast, Tecton, Hopsworks
- Data Quality: Great Expectations, Soda Core, Monte Carlo
- Data Validation: Evidently AI, WhyLogs, Amazon Deequ
Common 2025 Data Preparation Mistakes to Avoid
- Ignoring Data Drift: Not monitoring for concept and data drift in production
- Privacy Violations: Failing to anonymize sensitive data properly
- Bias Amplification: Not testing for and mitigating dataset biases
- Over-engineering: Creating too many features without business context
- Pipeline Complexity: Building overly complex data preparation pipelines
The Complete 2025 Data Preparation Checklist
Before model training, verify:
- ✅ Data quality score > 95%
- ✅ No data leakage between splits
- ✅ Feature importance validated
- ✅ Bias and fairness assessed
- ✅ Data drift monitoring in place
- ✅ Pipeline documented and reproducible
- ✅ Compliance requirements met
- ✅ Performance benchmarks established
Conclusion: Data Preparation as Competitive Advantage
In 2025, data preparation is no longer just a preliminary step—it’s a strategic competitive advantage. Organizations that master data preparation:
- Deploy models 3x faster with higher accuracy
- Reduce maintenance costs by 40-60%
- Achieve regulatory compliance more easily
- Build more trustworthy and ethical AI systems

The framework outlined in this guide represents the current state-of-the-art in data preparation. By implementing these 8 steps, you’ll be building on the solid foundation that separates successful, production-ready ML systems from academic experiments.
Remember: in the AI-driven world of 2025, your data preparation capability determines your AI capability. Invest in mastering this crucial skill, and you’ll be positioned to leverage the full potential of machine learning throughout this decade and beyond.
read more about How to Master Generative AI in 2025: A Complete Guide


GIPHY App Key not set. Please check settings